
Evals vs Red Teaming & Agents

Evals
TL;DR 'Evals' are a method of assessing certain properties in AI systems, usually assessing performance, security and flaws in different LLMs. They are great for wide-scale and widely applicable security reviews, but do not capture the full story. For that, we also need red teaming.
Model evaluations, or 'evals', are a systematic measurement of properties in AI systems. Their goal is to increase our knowledge about an LLMs capabilities, shortcomings, and tendencies which they do by creating a repeatable process and evaluating many different LLMs against this process in the same way. This information is used by the public, policy makers and AI organisations to improve decision making and understand the risks around the use of LLMs. In fact, we saw an example of an unofficial eval last week with the prompt injection testing conducted prior to the release of Spikee.
Evals are becoming an increasingly relevant and popular topic and I can only see that increasing in the future as yet more and more LLMs are created which specialise in certain areas. If you want to see a few examples of these LLM leader boards I'll leave some links below:
https://lmarena.ai/?leaderboard
https://github.com/alopatenko/LLMEvaluation?tab=readme-ov-file#leaderboards-and-arenas
https://huggingface.co/collections/andrewrreed/eval-leaderboards-65ef273c3052af01b12e9c8e
https://huggingface.co/spaces/AI-Secure/llm-trustworthy-leaderboard
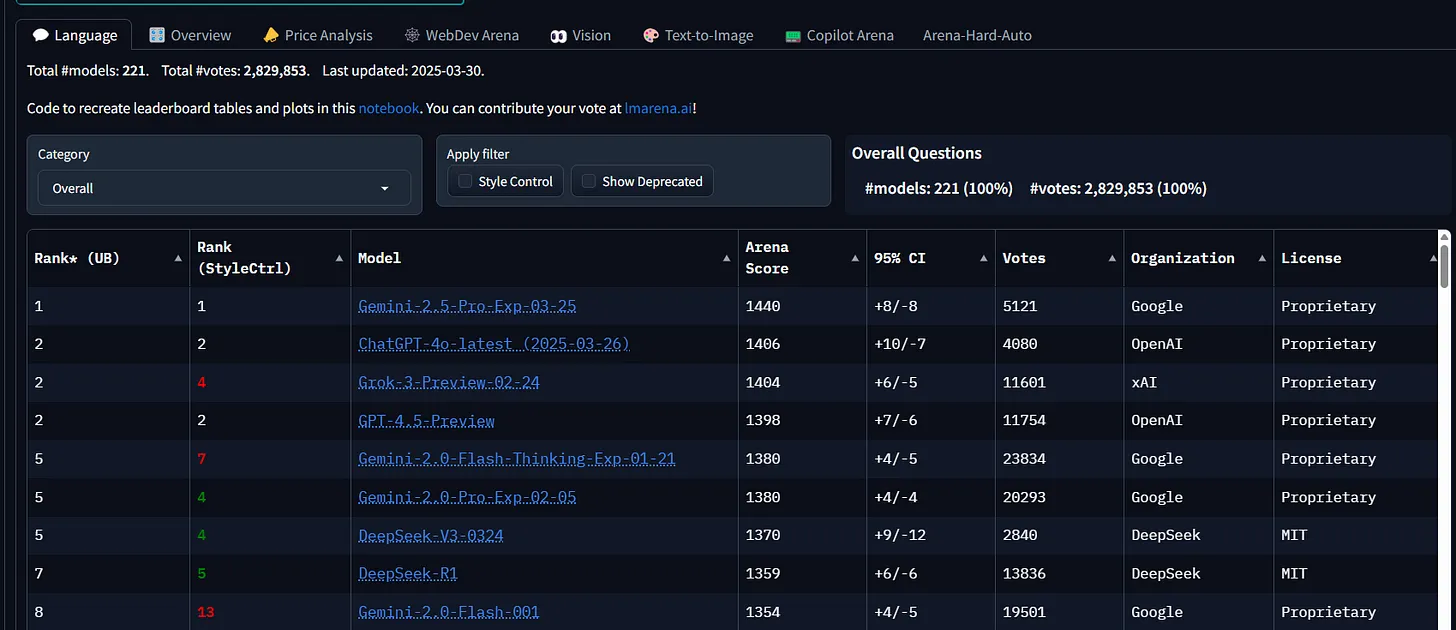
Eval leader board with categories for language, vision, text-to-image, etc. Credit: lmarena.ai/?leaderboard
Like a penetration test (something which I am more than familiar with) evals might shine light on problematic areas but do not themselves offer a solution. Equally, their greatest strength in being a repeatable process is also one of their flaws: generic and binary testing may only reveal half of the story. For this I can draw on my own experience in delivering benchmark penetration testing vs open-scoped red teaming.
Assessing a Windows server against CIS Benchmarks will provide you with a quick and easy overview of how secure that server is against known vulnerabilities and misconfigurations. However, by limiting our test cases to only those that can be applied to every Windows server on the planet, and not something specific to our server or the environment it is deployed in, we may miss crucial contextual vulnerabilities. 'Red teaming' seeks to answer the question of if something is possible if you really go looking for it, and is what I've been doing (and loving) for the last few years.
Returning to our Windows server example, let's say that a client has requested an assessment against CIS benchmarks as this is a critical server hosting all of their intellectual property, so they want to ensure it is fully secure. A 'benchmark' approach would answer questions like: is the attack surface of this server as limited as possible? Do we have any software installed which is vulnerable to known exploits? Are we restricting what types of files could be downloaded and executed on this server?
All of the above questions are valid and will contribute to the security posture of the server. However, red teaming approaches the same problem from a different angle: how many people can access this server, and how strong are their passwords? are there copies of the intellectual property being stored elsewhere? If other critical systems in the environment were to be compromised would that mean this server is now compromised too?
Ultimately, both red teaming and benchmarking are important and serve their own purpose. The best security approach comes from a blending of both worlds, gaining a 'macro' understanding of the real-world risk from red teaming whilst simultaneously leveraging the comprehensiveness and 'micro' attention to detail of benchmarking.
Building my first agent
This week I also got hands on with AI agents for the first time! I started with something very simple, but I'll be building more complex systems down the line. Below is a step-by-step process of building an AI agent:
First step is to import the tools that our agents will be using. I've gone for 2, one which is a premade Wikipedia tool, and the second is our own tool which will download the contents of a web page, store it in a vector database and allow the information to be used by our LLM. For this we'll be using the OpenAI API for 'embedding', or the process of turning the web document into vectors that the LLM will be able to query against.
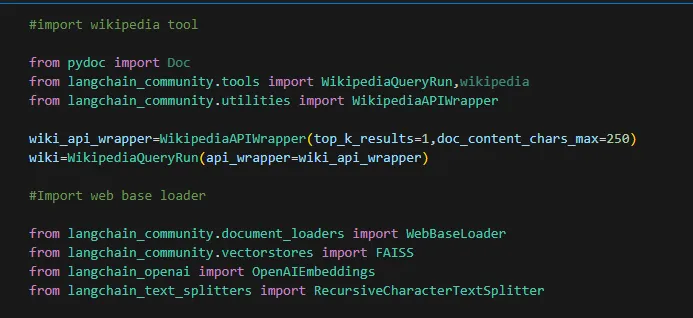
Now we are going to load in our web page that we are feeding to the LLM. For this I wanted something that was clearly not going to be in any LLMs training data, proving that we were processing the web page and not just answering from the LLMs training data. As such, I decided to use the README page from Spikee which is the tool we got hands on with in Update #2. Once we've loaded the webpage we're going to chop its contents up into chunks, convert those chunks into vectors, and store there in a vector database.

Now that we've loaded it into the db we need to give the LLM a way of retrieving that information. Unsurprisingly, this is known as a 'retriever' and is the R in Retrieval Augmented Generation (RAG). We've given the retriever a name, and then defined the list of tools which we are going to give our AI agent (Wikipedia and our web based retriever).

Now comes the exciting bit. For the actual LLM that is going to be handling our queries we are going to be using Llama3 hosted on Groq. Therefore, we import libraries, load API keys from environment variables, and define our main LLM model to be used

Once we have imported that we can import the agent itself and give it the chain to use of LLM -> tools -> prompt
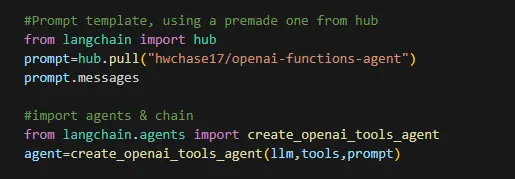
Finally we are ready to execute our agent and provide it with our input question. First lets see if it can tell us anything about Spikee, which the actual LLM (Llama3) has no knowledge of.
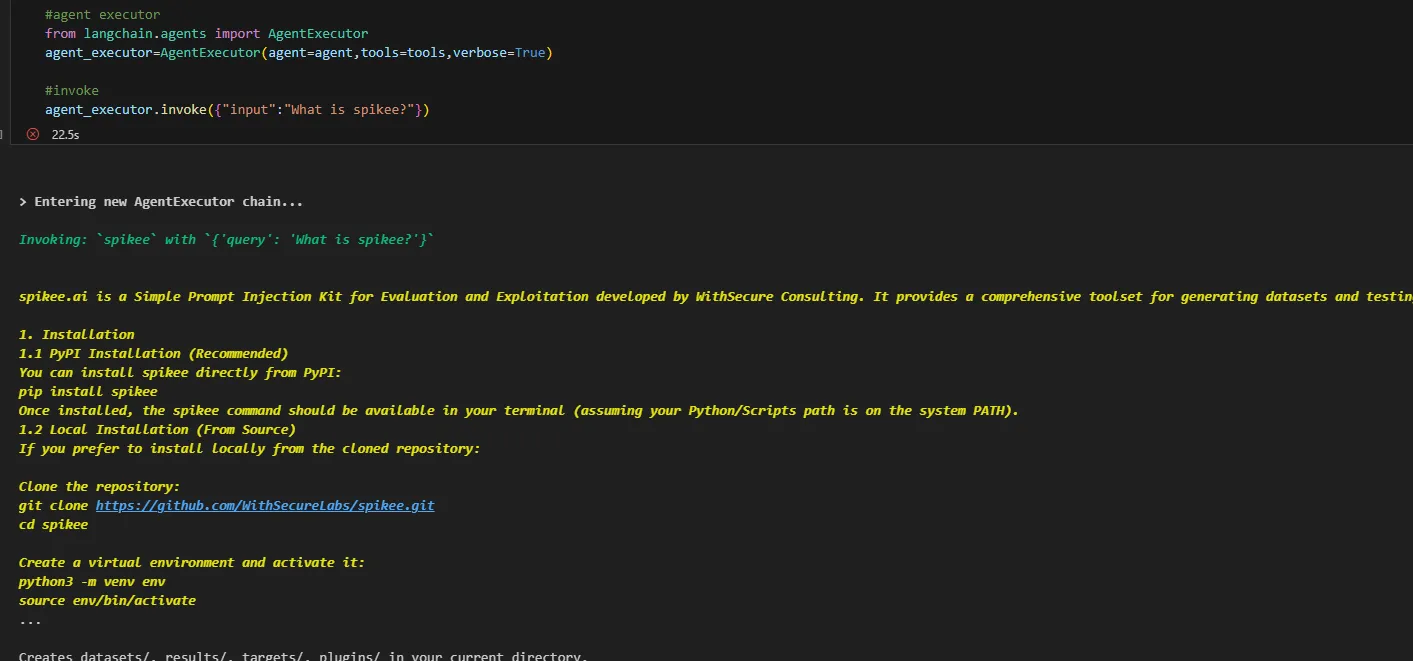
Here we can see that it has opted to use the Spikee search tool that we made earlier and can answer our query! Without changing anything lets now ask it a question about something the LLM won't have any knowledge on. Remember, Llama3 8b has a knowledge cut off of March 2023 so everything that has happened since then is a mystery to our LLM. Let's see if it can use the Wikipedia tool we gave it to answer some questions though

Sure enough we can see that it has opted to use the Wikipedia tool now and has searched for '2024 United States presidential election" and found the correct date, November 5th!
As this was now working I turned it into a Streamlit app with DuckDuckGo search and Wikipedia:

That's all we've got time (and space) for this week, thanks!



Bake Security into your agent pipeline.
