
Distillation Attacks

This week we’re going to be covering an AI risk that only really affects the frontier AI providers who are locked in an arms race to get to AGI, ASI and beyond. This is the idea that you can essentially improve your AI by using your competitors AI to train it up, known as ‘model distillation’.
Why are we talking about model distillation this week? Well, both Anthropic and Google came out publicly this week and directly called out frontier Chinese labs for trying to illicit Claude’s capabilities to improve their own models. Specifically, they called out DeepSeek, Moonshot and MiniMax.
Now, for those who have been here since before DeepSeek first dropped their first ‘viral’ model DeepSeek-R1 you will remember that at that time there was a lot of controversy for them doing this back in Jan 2025. OpenAI and Anthropic both accused DeepSeek of using distillation to train their own models, for a fraction of the price.
How does model distillation work?
Model distillation works by a type of compression where a small ‘student’ model is trained to mimic a large, complex ‘teacher’ model. This is a completely legitimate activity and is often used to reduce the size of models - it’s something we’re doing here at Secure Agentics!
However, the difference here is that we’re using two of our own models to try to get the ‘big’ model to impart its wisdom onto the ‘smaller’ model, which essentially learns to replicate the big model behaviour without having to go through the same lengthy training process and ‘shortcut’ to just imitating it. That is to say, instead of training on raw data and ‘hard’ correct/incorrect labels the student model uses ‘soft labels’ or probabilities.
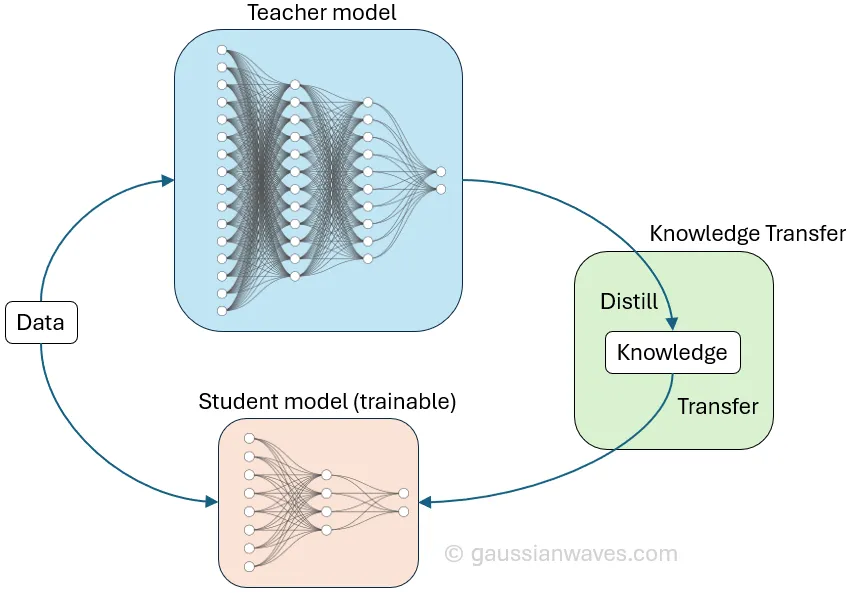
The student model compares its own responses with that of the bigger model until it learns to mimic it’s answers and can also attempt to extract the models reasoning (it’s thought process) which really illuminates how the model arrived at an answer. One thing you can’t do, obviously, is use a competitor’s model to train up a much smaller, cheaper model that mimics it and undercut them. This is strictly against terms of service agreements.
Scale
So, understanding what these Chinese labs were doing and why, how bad was this AI-stealing campaign? Well, Anthropic alone received over 16 million exchanges with Claude through 24k accounts. Google also reported the same sort of attacks against their Gemini models, which involved over 100k prompts targeted at cloning the internal reasoning logic capabilities.
This was just what has been reported in recent weeks, but given that DeepSeek seems to have a history of this dating back to their very first model releases this is certainly something which is happening constantly in the background.
The Downfalls of Model Distillation
Is that it then? China have copied American & British AI models on the cheap and now they are able to give them away for free and get everyone flocking? Not exactly. This is one of the intricacies of model distillation. When you distil a model from parent to child (even when you are doing so with complete access / control over both of these models which the Chinese will not have had) you are essentially creating a small model which can mimic the outputs of larger models.
Back in the GenAI era this was pretty compelling, as most people were just asking AI to answer questions. For simple, static tasks distilled models were pretty good. However, mimicking something does not equate to understanding or being able to replicate it’s deep reasoning, adaptability, and more complex capabilities. For example, a large part of the latest claude model (Opus 4.6) was around agentic capabilities, multi-agent collaboration, long-running workflows, parallel execution, etc. These are not the sort of capabilities that can be very easily cloned simply by looking at the model output and trying to get your model to do the same.
As you can imagine, therefore, leveraging these cloned models will unlikely produce the same results as the ones which were used to train them, especially for the more complex tasks, edge cases and non-evaluation-based testing.
The Irony
Before closing out I wanted to just call out one slight bit of hypocrisy in many of the frontier labs like Anthropic and Google who are now calling out this behaviour from the Chinese labs, stating that it is essentially training up models using things that they do not have the right to train from.
Well, it’s probably worth reminding you that many of the western frontier models from OpenAI, Google, Meta and Anthropic were trained up (in part) on public internet posts, proprietary / paywalled material, copyrighted books/blogs/research, etc. How many of the original authors of this profited? None. In fact, StackOverflow which was the absolute go-to place for discussing all things related to coding before AI (which was the main treasure trove that the coding agents were trained up on) was almost entirely killed off by the proliferation of AI in coding and they gained nothing from it whatsoever.
So, a pinch of salt required for some of the claims that the Chinese labs do not have the rights to train their models as many of the ‘parent’ models were the result of some unclear legal circumstances, lack of licenses or consent.
For now though that’ll do it, and we’ll catch you next week!



Bake Security into your agent pipeline.
